
22. 从零构建 GPT 模型#
22.1. 任务介绍#
在这一章节中,我们将从零构建并训练一个 GPT 语言模型,你将会掌握大模型底层原理(包括模型结构、训练过程)和核心机制(如采样生成策略),从而深入理解语言模型的本质,彻底摆脱“调包侠”的困境。
22.2. 什么是语言模型?#
语言模型就是用来计算一个句子或一串词语出现的概率的模型。简单来说,它通过学习大量的文本,来学会什么样的词组合在一起是“通顺”的、是“合理”的。
为了帮助你更好地理解,我们可以把它想象成一个“超级猜词大师”。这个大师会根据你给它的上下文(前面的词或句子),来预测下一个最有可能出现的词。
想象我们在玩一个猜词游戏:
我说:“今天天气很__”
你几乎会脱口而出:“好”、“热”、“冷”、“不错”。
你是怎么猜到的?因为你根据平时的语言习惯,知道在这些词里,“今天天气很好”是出现概率最高的。你不会猜“今天天气很桌子”,因为这句话不合逻辑。
语言模型干的就是这件事。 它读了海量的文本,从中学会了词语之间的搭配规律。当你给它一个上文时,它就能预测下一个最可能出现的词是什么。
22.3. 语言模型的核心#
语言模型的核心就是计算概率。从数学角度看,语言模型的目标是为一个词序列(比如一个句子)\(w_1, w_2, \ldots, w_n\) 赋予一个概率 \(P(w_1, w_2, \ldots, w_n)\)。
这个概率可以理解为这句话有多“像人话”。例如:
\(P(\text{我今天吃了苹果})\) 的概率会很高。
\(P(\text{苹果吃了我今天})\) 的概率会非常低,接近于0。
为了计算整个句子的概率,模型通常使用链式法则,将它拆解为一步步的条件概率:
其中,\(w_1, w_2, w_3, w_4\) 分别代表“我”、“今天”、“吃了”、“苹果”。
所以,语言模型的核心任务就是计算这个条件概率:给定前面的词,下一个词是什么?
22.4. 什么是大语言模型?#
“大语言模型”这一名称中的“大”字,既体现了模型训练时所依赖的庞大数据集,也反映了模型本身庞大的参数规模。这类模型通常拥有数百亿甚至数千亿个参数(parameter) 。当前的大语言模型通常是基于 Transformer 架构通过海量文本数据训练获得。
GPT(Generative Pre-trained Transformer)是一种基于 Transformer 架构的大语言模型,由 OpenAI 于 2018 年发布。GPT 模型的参数规模通常在数十亿到数千亿之间,具体数量取决于模型的版本。
大语言模型的构建通常分为两个阶段:预训练(Pre-training)和微调(Fine-tuning)。
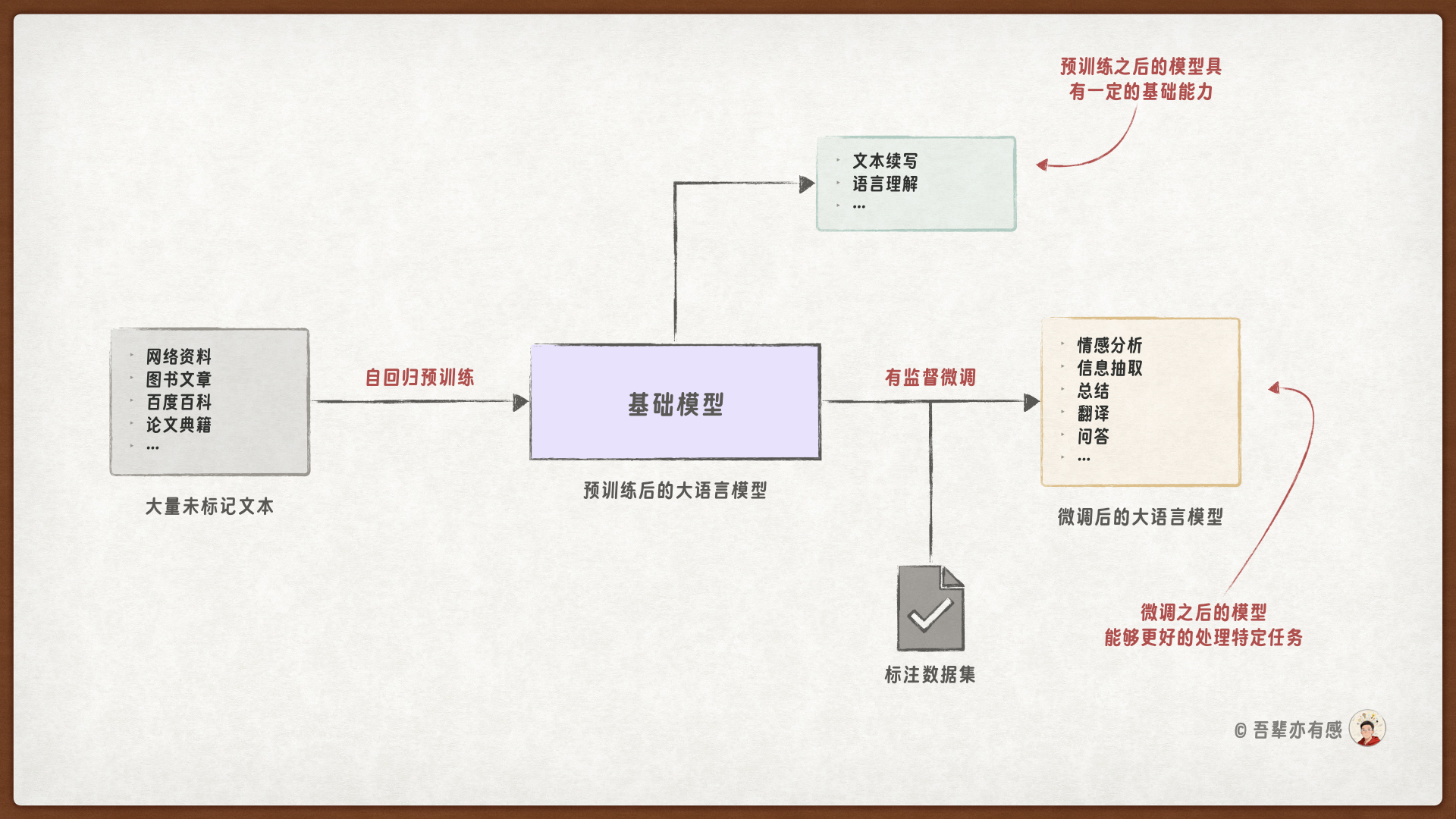
预训练阶段:在预训练阶段,模型会在标注数据的情况下,通过自回归任务学习大规模文本数据,建立起对语言的理解和生成能力。预训练的目标是让模型学会语言的统计特征和模式。
微调阶段:在微调阶段,模型会在有标注数据的情况下,使用特定任务的数据集进行训练。微调的目标是使模型在特定任务上表现出更好的性能。
预训练是大语言模型的首个训练阶段,完成预训练的大语言模型通常被称为基础模型(foundation model)。在本次任务中,我们将聚焦于从零开始深入剖析大语言模型的工作原理,并通过预训练的方式亲手实现一个具备文本生成能力的 GPT 模型。
22.5. GPT 模型概述#
GPT 最初是由 OpenAI 的 Radford 等人在论文“Improving Language Understanding by Generative Pre-Training”中提出的。GPT 模型仅在相对简单的下一单词预测任务上进行了预训练,就拥有了非常强大而全面的语言理解能力。
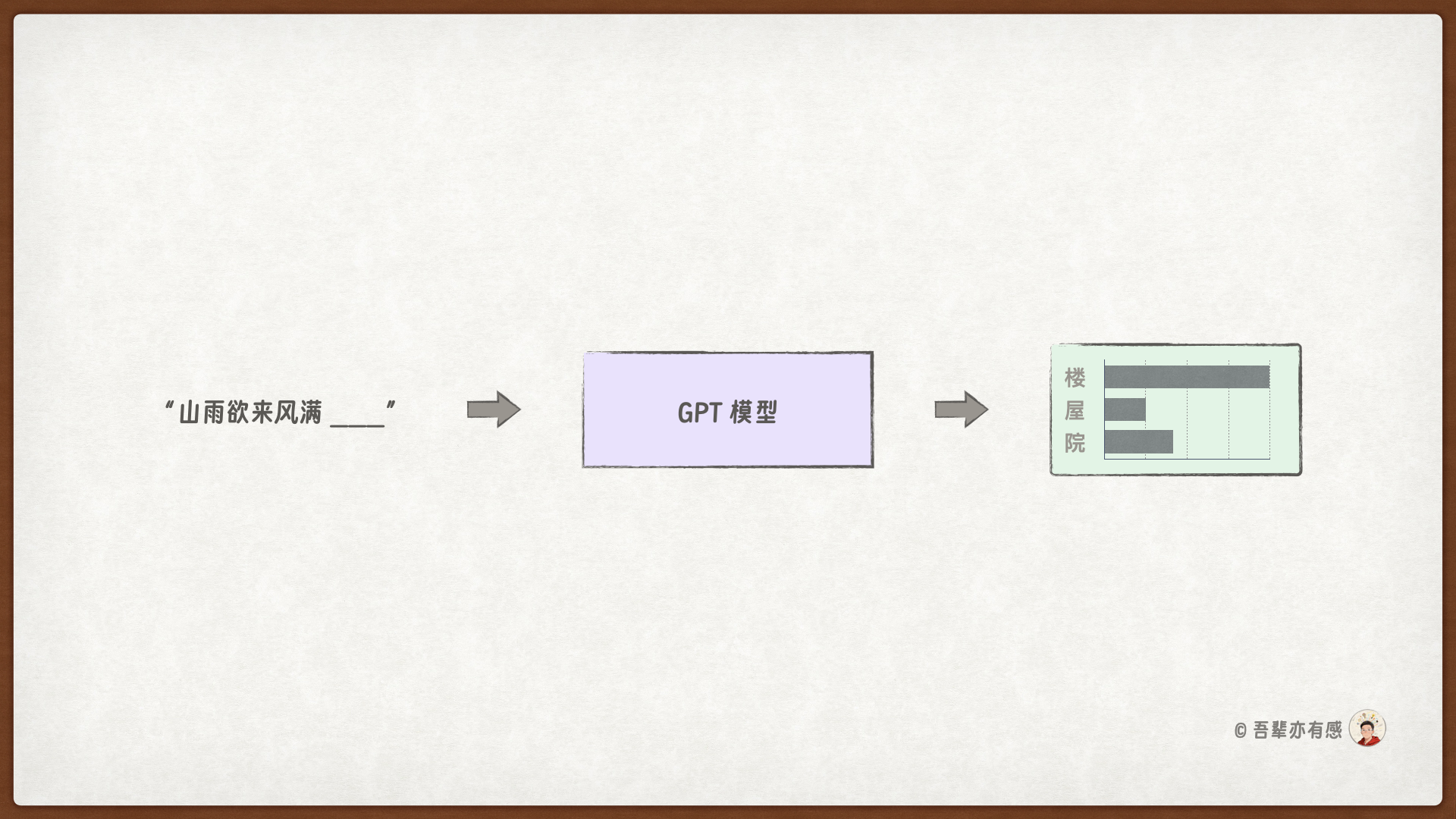
在 GPT 模型的下一单词预测预训练任务中,系统通过观察之前的词来学习预测句子中的下一个词。这种方法能够帮助模型理解词语和短语在语言中的常见组合,从而为应用于各种其他任务奠定基础。
所以 GPT 只包含 Tansformer 的解码器部分,并不包含编码器。由于像 GPT 这样的解码器模型是通过逐词预测生成文本,因此它们被认为是一种自回归模型(autoregressive model)。自回归模型将之前的输出作为未来预测的输入。
22.6. 构建大语言模型#
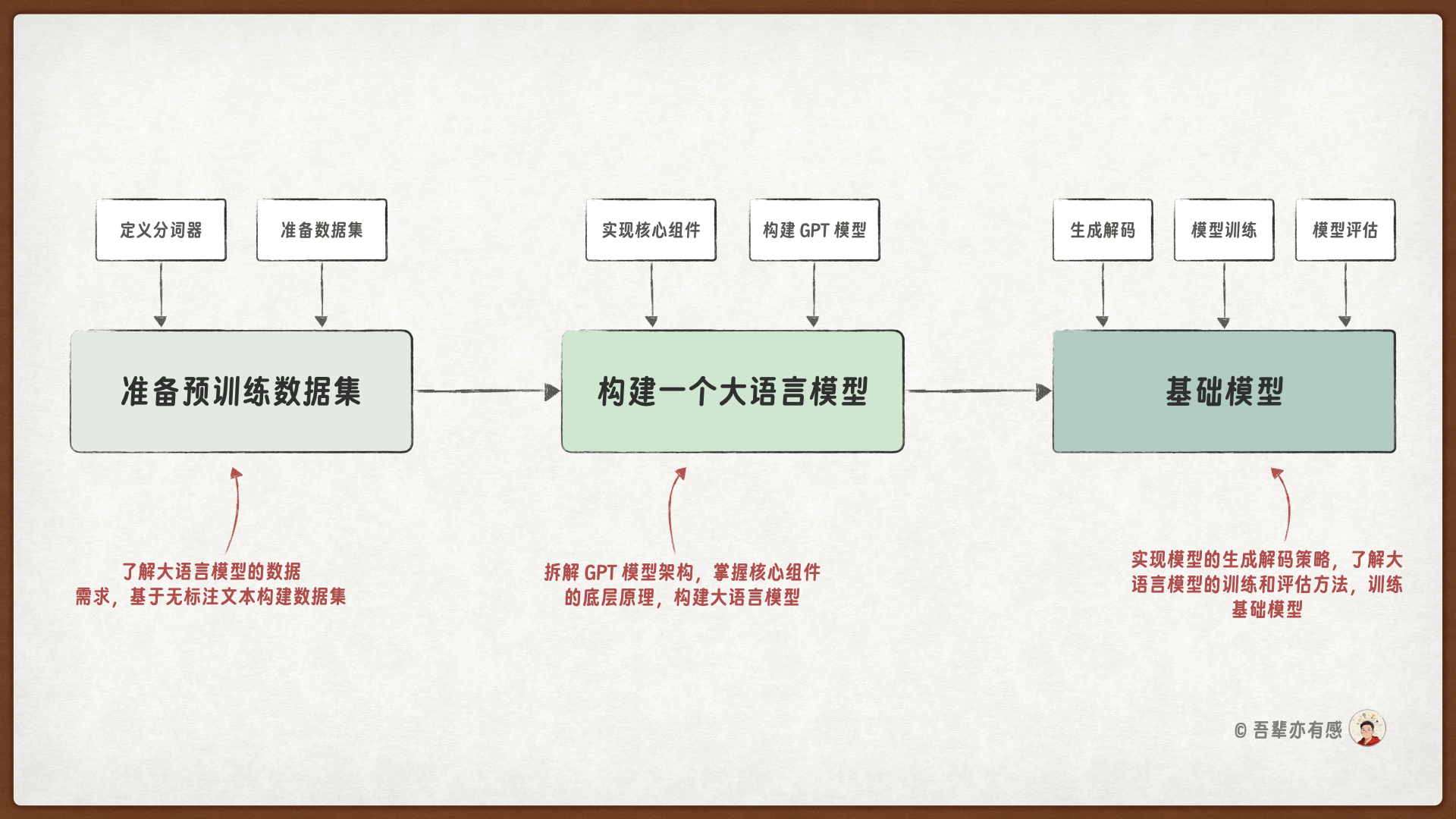
构建大语言模型通常包含三个关键阶段:首先是模型架构实现与数据准备阶段(第一阶段),其次是通过预训练大语言模型以获取基础模型阶段(第二阶段),最后是对基础模型进行微调以适配特定任务阶段(第三阶段)。
本次实战将重点聚焦于第一阶段和第二阶段,即通过预训练获取基础大语言模型的完整流程。
在第一阶段,我们将学习数据预处理的基本流程,并动手实现大语言模型的核心组件,构建一个完整的 GPT 模型。
在第二阶段,我们将探索如何预训练一个具备文本生成能力的类 GPT 大语言模型,同时探讨大语言模型的评估基础知识,优化模型的生成策略。
我将这两个阶段的内容划分为三个主要部分:
第一部分:准备预训练数据集
第二部分:构建大语言模型结构
第三部分:预训练并评估大语言模型
从头开始预训练一个大语言模型并非易事,尤其是像 GPT 这类模型的训练成本非常高昂。由于本项目的重点在于教学演示,我们将使用规模较小的数据集进行训练,以便更清晰地展示整个流程。
22.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。